文章总述
主要是总结平时在使用python过程中遇到的编码问题
- 1-写入文件时报UnicodeEncodeError
- 2-在scrapy框架中用xpath解析时print打印出来是Selector对象
- 3.\x开头编码的数据解码成中文
1 写入文件时报UnicodeEncodeError
1.1 问题描述
UTF-8编码的字符串,不能写入文件中,当向一个文件写入时,可能会遇到以下问题:
Traceback (most recent call last): File “.py“, line , in f.write(…) UnicodeEncodeError:’ascii’ codec can’t encode characters in position <…>: ordinal not in range(…)
1.2 解决方法一
1.文件声明为 #coding=utf-8
2.开头重新载入编码,代码如下:123import sysreload(sys) sys.setdefaultencoding('utf-8')
3.加入写入文件代码1file=open('<your filename>','w') #<your filename>是你想要写入的文件名字.
1.3 解决方法二
1.导入模块codecs: import codecs,codecs专门用作编码转换.codecs官方文档
2.以utf8编码打开文件
|
|
1.4 原理
- 查看此处
2 在scrapy框架中用xpath解析时print打印出来是Selector对象
2.1 问题描述
在scrapy框架中用xpath解析时print打印出来是Selector对象,代码如下:
|
|
- 打印的结果如下:
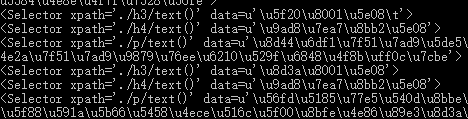
2.2 解决方法
- 将xpath解析后获得的列表或列表中的元素运用extract()方法(),修改后的代码如下:
|
|
2.3 原理
- 在scrapy框架中,xpath解析后返回的不是列表list对象,而是SelectorList对象(是内建list类的子类)
- SelectorList中的每个元素都是Selector对象,所以打印出来的是Selector对象
- 而extract方法是SelectorList对象和Selector对象的方法,可以把SelectorList对象转换成list类型,可以把Selector对象转换成unicode字符串
- 参考: 爬虫:Scrapy5 - 选择器Selectors && xpath解析使用extract()的时候,几种情况有点分不清楚
3 \x开头编码的数据解码成中文
3.1 问题描述
在python中输出的中文是以\x开头编码的
|
|
3.2 解决方法
- \x对应的是UTF-8编码的数据,通过decode(‘utf-8’)转化规则可以转换为Unicode编码,unicode再用print打印出来即可
- 如果是列表,不要直接打印列表,而应print列表中的元素